Hallo,
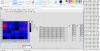
aufgrund der fortgeschrittenen Zeit würde ich von einer kompletten Umstrukturierung lieber absehen. Den Fehler mit dem CSV-File konnte ich beheben, indem ich den Datenfluss an der richtigen Stelle aufhalte. Und somit stimmen die Werte in der Tabelle, die ich inzwischen mit Python geplottet habe:


Da sieht man auch gut die Abweichungen für kleinere Schritte, weshalb eine Statemachine zum Warten bis der Motor an der richtigen Position angekommen ist, zu Problemen führen könnte.
Nichtsdestotro würde ich gerne auch die z-Matrix fehlerfrei darstellen, um eine "richtige" Intensitätsmatrix zu bekommen und nicht nur das CSV-File. Ich frage mich vorallem, wie diese Sprünge darein kommen und woher die 0 kommen, die in der Tabelle gar nicht zu sehen sind. Kann das auch ein Timimg-Problem sein? Da es sich da ja um eine Zählrate handelt, kann das durchaus die unterschiedlichen Werte erklären, oder?
Vielleicht kann man diesen Wert ja zeitlich irgendwie mitteln über zum Beispiel 1000ms und dann diesen gemittelten Wert weitergeben? Sodass in das z-Array und in die Tabelle jeweils der gleiche, gemitteltete Wert geschrieben wird.
Hier ist noch eine Notiz aus der Library für den Detektor:
Zitat:Note: Observe that most of the PH_xxxx library calls must be made sequentially in exactly the right order. They cannot be called
in parallel as is the default in LabVIEW. Typically this is achieved by sequence structures or data flow dependency
Was ich jetzt noch geändert habe, ist eine flache Sequenzstruktur in der inneren For-Loop. Im ersten Rahmen wird der Motor bewegt und etwas gewartet, dann werden im zweiten Rahmen die Positionen der Achsen und der Messwert (Zählrate) abgefragt, die dann in den dritten Rahmen übergehen, wo die Daten (Positionen und Messwert) dann einmal in die Tabelle geschrieben werden und die Messwerte an die richtige Stelle des Arrays geschrieben werden. So ist es zwar nicht zeitlich gemittelt. Aber so erhoffe ich mir, dass zumindest der gleiche Wert in Z-Array und ins CSV-File geschrieben werden, weil die Rahmen ja erst durchgeführt werden, wenn alle notwendigen Daten anliegen. Mache ich mir da zurecht Hoffnung?
Allerdings sprechen diese Regelmäßigkeiten, die im Vergleich von Tabelle und z-Matrix auffallen, ja eher für eine falsche Implementierung..

 /
Positionen (Werte) in Matrix speichern
/
Positionen (Werte) in Matrix speichern






