|
15.07.2020, 13:54
 Beitrag #1 Beitrag #1 |

dimitri84

Astronaut

Beiträge: 1.496
Registriert seit: Aug 2009
2020 Developer Suite
2009
DE_EN
53562
Deutschland
|
unicode in XML Datei wird als ANSI eingelesen
Hallo zusammen,
ich benutze eine ActivX lib um XML Dateien zu lesen. (Haben da schon einiges probiert und diese Variante ist sehr perfomant.)

In meinem xml Editor sieht das so aus:
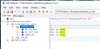
In LV ist vom unicode aber nix mehr zu sehen:
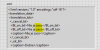
Was kann ich tun um in LV unicode zu lesen?
  MSMXL_open_xml_file.vi MSMXL_open_xml_file.vi (Größe: 32,13 KB / Downloads: 326)
  default_ch.xml.txt default_ch.xml.txt (Größe: 958 Bytes / Downloads: 322)
Beste Grüße
dimitri
„Sag nicht alles, was du weißt, aber wisse immer, was du sagst.“ (Matthias Claudius)
|
|
|
|
15.07.2020, 14:13
(Dieser Beitrag wurde zuletzt bearbeitet: 15.07.2020 14:14 von GerdW.)
Beitrag #2
|

GerdW
______________

Beiträge: 17.515
Registriert seit: May 2009
LV2019 (LV2021)
1995
DE_EN
10×××
Deutschland
|
RE: unicode in XML Datei wird als ANSI eingelesen
Hallo Dimitri,
ich vermute, dass dein ActiveX-Tool diese Konvertierung vornimmt und LabVIEW damit nichts/wenig zu tun hat…
Wenn ich dein XML per ReadTextFile in LabVIEW lese, siehst man nämlich folgendes (Ausschnitt):
Code:
Anzeige in \-code display: z\00a\00\n\01o\00 (Unicode für začo)
Dein Screenshot der LabVIEW-Anzeige zeigt aber deutlich ein "normales c": diese Konvertierung zu ASCII wurde nicht von LabVIEW durchgeführt, sondern wird von der ActiveX-Komponente geliefert…
|
|
|
|
|
16.07.2020, 07:37
Beitrag #3
|
|
|
|
|
|
16.07.2020, 08:33
Beitrag #4
|

jg
CLA & CLED
Beiträge: 15.864
Registriert seit: Jun 2005
20xx / 8.x
1999
EN
Franken...
Deutschland
|
RE: unicode in XML Datei wird als ANSI eingelesen
Nun gut, LabVIEW ist nicht wirklich Unicode fähig, alle Strings sind nur 8-bit...
Außer du stellst da gewisse Ini-Werte anders ein, aber da kenn ich mich auch nicht genau aus. Und was ich bisher so gelesen haben, zu 100% funktioniert das auch nicht.
Gruß, Jens
Wer die erhabene Weisheit der Mathematik tadelt, nährt sich von Verwirrung. (Leonardo da Vinci)
!! BITTE !! stellt mir keine Fragen über PM, dafür ist das Forum da - andere haben vielleicht auch Interesse an der Antwort!
Einführende Links zu LabVIEW, s. GerdWs Signatur.
|
|
|
|
|
16.07.2020, 09:27
Beitrag #5
|
|
|
|
|
16.07.2020, 10:13
(Dieser Beitrag wurde zuletzt bearbeitet: 16.07.2020 10:13 von Martin.Henz.)
Beitrag #6
|

Martin.Henz
LVF-Team
Beiträge: 442
Registriert seit: Jan 2005
2.5.1 bis 20
1992
kA
74363
Deutschland
|
RE: unicode in XML Datei wird als ANSI eingelesen
Hast du dir einmal den NI XML Parser unterhalb der File I/O Palette angesehen? Die machen das nicht so viel anders als wie in deinem VI, jedoch bekomme ich bei Abruf von "XML" (nicht "text") auch Unicode. Das verhält sich teilweise etwas anders. Ich will da aber ohne aktuelle Not nicht unnötig viel Zeit rein stecken :-)
|
|
|
|
|
16.07.2020, 12:20
Beitrag #7
|
dimitri84
Astronaut
Beiträge: 1.496
Registriert seit: Aug 2009
2020 Developer Suite
2009
DE_EN
53562
Deutschland
|
RE: unicode in XML Datei wird als ANSI eingelesen
Hallo Martin,
die zwei VI's hier lesen unicode, ja.
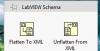
Aber da fehlen einem sämtliche Freiheitsgrade. Fügt man etwas hinzu muss man Quellcode anpacken. Man kann nicht gezielt einzelne Elemente lesen.
Diese Palette macht es genauso falsch (Ist aber zusätzlich zur ActivX Lösung wesentlich langsamer):
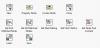
Gruß
dimitri
„Sag nicht alles, was du weißt, aber wisse immer, was du sagst.“ (Matthias Claudius)
|
|
|
|
|
16.07.2020, 12:55
Beitrag #8
|
jg
CLA & CLED
Beiträge: 15.864
Registriert seit: Jun 2005
20xx / 8.x
1999
EN
Franken...
Deutschland
|
RE: unicode in XML Datei wird als ANSI eingelesen
Ich weiß nicht, ob es dir weiterhilft, aber im VIPM gibt es 2 unicode-Tools, von JKI und NI.
Gruß, Jens
Wer die erhabene Weisheit der Mathematik tadelt, nährt sich von Verwirrung. (Leonardo da Vinci)
!! BITTE !! stellt mir keine Fragen über PM, dafür ist das Forum da - andere haben vielleicht auch Interesse an der Antwort!
Einführende Links zu LabVIEW, s. GerdWs Signatur.
|
|
|
|
|
16.07.2020, 13:26
Beitrag #9
|
|
|
|
|
|
17.07.2020, 07:52
|
dimitri84
Astronaut
Beiträge: 1.496
Registriert seit: Aug 2009
2020 Developer Suite
2009
DE_EN
53562
Deutschland
|
RE: unicode in XML Datei wird als ANSI eingelesen
(16.07.2020 12:55 )jg schrieb: Ich weiß nicht, ob es dir weiterhilft, aber im VIPM gibt es 2 unicode-Tools, von JKI und NI.
Gruß, Jens
Viele dieser VI's haben wir in der Vergangenheit so ähnlich selber programmiert - interessant. Aber helfen tun die in diesem Zusammenhang nicht.
Wir machen jetzt Folgendes (nicht wirklich toll ...): Wir konvertieren den unicode string in ein Byte-Array und speichern die Byte-Werte selbst in der XML (2 byte pro Zeichen). Nicht schön. Im normalen Editor nicht vom Menschen lesbar ... aber mittelfristig programmieren wir noch ein spezielles Editor-Programm, welches dann den Inhalt zum Anzeigen wieder in lesbare strings wandelt.
Wie gesagt, nicht schön, aber wollten xml auch nicht ganz verwerfen.
Beste Grüße
„Sag nicht alles, was du weißt, aber wisse immer, was du sagst.“ (Matthias Claudius)
|
|
|
|
| |

 /
unicode in XML Datei wird als ANSI eingelesen
/
unicode in XML Datei wird als ANSI eingelesen



