Hallo zusammen!
Gibt es hier SQL-Cracks?
Ich hab folgendes Problem: Ich habe ein LV-Programm geschrieben, mit dem man Daten aus einer großen SQL-Server Tabelle (Einige Millionen Datensätze) abfragen kann.
Die Abfrage sieht dann mit verschiedenen Filterkriterien ungefähr so aus:
SELECT p.PPunktNr, p.Beschreibung, g.Ist, p.Soll, p.MaxWert, p.MinWert, p.Toleranz, g.Status, g.GerNr, g.Pruefdatum, g.Pruefablauf, ge.GerTyp, ge.WMNr FROM tbl_Pruefpunkt p INNER JOIN tbl_Geraete ge INNER JOIN tbl_GerPruefPunkt g ON ge.GerTypIDCnt = g.GerID ON p.PPunktIDCnt = g.PPunktID WHERE g.PPunktID IN (1173) AND g.GerID = 109 AND g.Status != 0 AND g.Pruefablauf = 'Prüfung Produktion' ORDER BY p.PPunktNr, g.GerNr
Tabellen:
tbl_Pruefpunkt p enthält Stammdaten, ca. 2000 Datensätze
tbl_Geraete ge enthält Stammdaten, ca. 100 Datensätze
tbl_GerPruefPunkt g enthält Ergebnissdaten, mehrere Millionen Datensätze
weitere Infos:
SQL Server 2000
LV 2009
Verbindung mittels Microsoft Native Client 9 (per OLE)
Für SQL Kommunikation verwende ich das ADO TOOL von IBB:
http://forum.ib-berger.com/index.php?showforum=12
Folgendes Verhalten ergibt sich:
Frage ich Geräte ab, zu denen nur wenige Datensätze existieren (GerID), geht die Abfrage relativ schnell (z.B. 3 s, erneute Abfrage um Faktor 100 beschleunigt). Bei Geräten mit mehr Datensätzen (GerID=xy) verlangsamt sich das ganze dramatisch (z.b. 190s, erneute Abfrage genau so lahm).
Dabei ist egal, wie viele Datensätze tatsächlich übertragen werden. Scheinbar dauert das Erstellen eines Recordsets so lange. Das Auslesen der Zeilen mittels getRows geht dann schnell.Ist auch in diesem Bild ganz gut zu sehen:
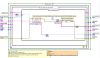
Das Programm steckt sehr lange in dem linken Teil bis die Referenz auf ein recordset ausgegeben wird.
Frage ich Werte ohne joins direkt ab mit z.B.:
SELECT g.Ist, g.Status, g.GerNr, g.Pruefdatum, g.Pruefablauf FROM tbl_GerPruefPunkt g WHERE g.PPunktID IN (1173) AND g.GerID = 109 AND g.Status != 0 AND g.Pruefablauf = 'Prüfung Produktion' ORDER BY g.GerNr
geht das Ganze auch nicht schneller. Daher vermute ich mal, dass es nicht wirklich an der Art und Weise der Abfrage liegen kann. Vom Netzwerktraffic scheint es auch nicht wirklich abhängig zu sein, da das Holen von 200 Zeilen genau so lange dauert, wie das von 200.000 zeilen.
Gibt es eine Möglichkeit, das Erstellen eines Recordsets in der DB zu beschleunigen? Müssen da evtl. noch Indizes gesetzt werden etc...?
Ach ja: Frage ich per Eigenschaftsknoten die Einstellungen des Cursors ab ist dieser auf server, fast forward, read only eingestellt. Sollte eigentlich passen.
Irgendwelche Tipps?
Gruß,
Daniel









