' schrieb:Hallo @ all.
Ich habe ein großes zweidimensonales Array mit 4096x1000 Punkten. Daraus möchte ich die FFT berechnen. Die FFT wird aus den 4096 Punkten berechnet und das ganze dann 1000 mal. Ich habe mal ein einfaches Beispiel geschrieben. Dort erzeuge ich mir ein Testarray und lasse es von der FFT-Funktion berechnen. Wenn man auf den Parallelbutton klick, dann wird das Array in 2 gleich große Teile geteil und die FFT auf 2 CPU-Kernen berechnet, jedoch ist meien Version alles andere als super in der Performance. Ich messe die Zeit für die Berechnung der FFT mit 1 CPU-Kern und mit 2 CPU Kerne, die parallel arbeiten.
Mache ich etwas bei der Optimierung falsch?
Ich weiss nicht, sieht doch gut aus.
Ich messe auf meinen Athlon 64 5050e (also ein relativer aktueller Dual-Core Prozessor) bei "nicht-parallerer" Verarbeitung eine durchschnittliche Durchlaufzeit von etwas über 300 ms, bei paraller Verarbeitung dagegen knapp über 200 ms. Insgesamt also 50% schneller, das ist doch gut! Bedenke, dass du auch einiges an Zeit für das Aufteilen und vereinen der Arrays draufgeht.
Übrigens, wenn du die Abarbeitung eines Programmteils auf einem der Prozessoren erzwingen willst, dann musst du mit Timed-Sequences oder Timed-Loops arbeiten:
Könnte so aussehen:
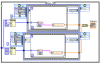
Übrigens, dein 2. Bsp. zeigt bei mir keinen Performance-Gewinn.
Gruß, Jens
EDIT: Die Build-Array Fkt. scheint besser zu sein als die von dir verwendete Insert-Into-Array










