|
11.08.2010, 08:16
 Beitrag #1 Beitrag #1 |
tanka

LVF-Grünschnabel

Beiträge: 39
Registriert seit: Jul 2009
8.6
-
de
95541
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
Hallo Leute,
noch eine Frage:
Über die serielle Schnittstelle erhalte und sende ich einen Datenstrom (1D- U8-Array).
Diese soll in und aus einem hierachischen Cluster mit unterschiedlichen Datentypen (Float[4][6], Int32, String, Int32, UInt16[4],...) geschrieben werden.
Ich habe die Funktion flatten/unflatten schon gefunden, allerdings enthält mein Bytestrom keine Header in denen die Längen angegeben sind, somit fällt diese Variante flach. 
Nun ist es ziemlich aufwendig den Datenstrom einzeln aufzudröseln bzw. zusammenzustricken und in den Cluster zu schreiben.
Gibt es eine Möglichkeit einen Bytestrom direkt in ein Cluster zu geben/nehmen, ohne diese Header mit Längenangaben?
Kann ich LV irgendwie auf schnellem Wege beibringen, wie der Bytestrom interpretiert werden soll?
Danke Danke
tank
|
|
|
|
|
11.08.2010, 08:22
Beitrag #2
|

jg
CLA & CLED

Beiträge: 15.864
Registriert seit: Jun 2005
20xx / 8.x
1999
EN
Franken...
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
' schrieb:Ich habe die Funktion flatten/unflatten schon gefunden, allerdings enthält mein Bytestrom keine Header in denen die Längen angegeben sind, somit fällt diese Variante flach.
Wieso fällt das flach? Flatten To String hat einen Eingang "Prepend Array Size" ( http://zone.ni.com/reference/en-XX/help/37...tten_to_string/ ). Dort ein False angeschlossen, und dein Cluster wird dir in einen U8-String umgewandelt. Jetzt musst du in der Definition des Clusters mit deinen Arrays nur auf die richtige Reihenfolge achten.
Alternativ, in der selben Palette, in der du Flatten To String gefunden hast, gibt es noch Typecast: http://zone.ni.com/reference/en-XX/help/37...lang/type_cast/
Gruß, Jens
Wer die erhabene Weisheit der Mathematik tadelt, nährt sich von Verwirrung. (Leonardo da Vinci)
!! BITTE !! stellt mir keine Fragen über PM, dafür ist das Forum da - andere haben vielleicht auch Interesse an der Antwort!
Einführende Links zu LabVIEW, s. GerdWs Signatur.
|


|
|
|
|
11.08.2010, 08:33
Beitrag #3
|
tanka
LVF-Grünschnabel
Beiträge: 39
Registriert seit: Jul 2009
8.6
-
de
95541
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
' schrieb:Wieso fällt das flach? Flatten To String hat einen Eingang "Prepend Array Size" ( http://zone.ni.com/reference/en-XX/help/37...tten_to_string/ ). Dort ein False angeschlossen, und dein Cluster wird dir in einen U8-String umgewandelt. Jetzt musst du in der Definition des Clusters mit deinen Arrays nur auf die richtige Reihenfolge achten.
Desswegen schrieb ich auch hierachischer Cluster. Denn da wird immer die Array-Größe eingefügt.
' schrieb:Alternativ, in der selben Palette, in der du Flatten To String gefunden hast, gibt es noch Typecast: http://zone.ni.com/reference/en-XX/help/37...lang/type_cast/
Kann ich bei Typcast denn auch einen hierachischen Cluster als Umwandlungstyp angeben?
|
|
|
|
11.08.2010, 08:38
(Dieser Beitrag wurde zuletzt bearbeitet: 11.08.2010 08:38 von GerdW.)
Beitrag #4
|

GerdW
______________
Beiträge: 17.497
Registriert seit: May 2009
LV2019 (LV2021)
1995
DE_EN
10×××
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
Hallo Tanka,
"Desswegen schrieb ich auch hierachischer Cluster."
Kannst du das mal genauer erläutern? Evtl. mit einem Link? Dieser Begriff (dieses Konzept) ist mir bisher noch nicht untergekommen...
Vielleicht einfach mal ein Beispiel(-CTL) anhängen?
|
|
|
|
|
11.08.2010, 08:53
Beitrag #5
|
jg
CLA & CLED
Beiträge: 15.864
Registriert seit: Jun 2005
20xx / 8.x
1999
EN
Franken...
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
Hallo, Tanka,
ich sehe gerade, meine Tipps waren nicht gut... Typecast mag einen solch verschachtelten Cluster nicht als Eingang, und bei FlattenToString sind trotz Eingang True doch die Array-Größen im ByteStream drin:

:hmm:Dann fällt mir nur auf die Schnelle ein, jedes Element des Clusters einzeln zu (Un)Flatten, und dann zusammenzusetzen.
Gruß, Jens
Wer die erhabene Weisheit der Mathematik tadelt, nährt sich von Verwirrung. (Leonardo da Vinci)
!! BITTE !! stellt mir keine Fragen über PM, dafür ist das Forum da - andere haben vielleicht auch Interesse an der Antwort!
Einführende Links zu LabVIEW, s. GerdWs Signatur.
|
|
|
|
11.08.2010, 09:29
(Dieser Beitrag wurde zuletzt bearbeitet: 11.08.2010 09:32 von Lucki.)
Beitrag #6
|
|
|
|
|
|
11.08.2010, 09:46
Beitrag #7
|
jg
CLA & CLED
Beiträge: 15.864
Registriert seit: Jun 2005
20xx / 8.x
1999
EN
Franken...
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
Auch diese Variante enthält die Array- und String-Größen im ByteStream.

Genau das will tanka nicht haben.
Gruß, Jens
Wer die erhabene Weisheit der Mathematik tadelt, nährt sich von Verwirrung. (Leonardo da Vinci)
!! BITTE !! stellt mir keine Fragen über PM, dafür ist das Forum da - andere haben vielleicht auch Interesse an der Antwort!
Einführende Links zu LabVIEW, s. GerdWs Signatur.
|
|
|
|
11.08.2010, 09:52
(Dieser Beitrag wurde zuletzt bearbeitet: 11.08.2010 09:54 von tanka.)
Beitrag #8
|
tanka
LVF-Grünschnabel
Beiträge: 39
Registriert seit: Jul 2009
8.6
-
de
95541
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
@lucki:
An den Variant Datentyp dachte ich auch schon, allerdings ist mir auch bei diesem Datentyp nicht ganz ersichtlich, woher LV weiß, wie der eingehende Datenstrom zu interpretieren ist.
Gut wäre wenn ich z.B per Cluster-Konstante meine Datenstruktur vorgebe und der Bytestream dann entsprechend interpretiert wird.
@Gerdw:
Hier ein Auszug aus der Hilfe zur Problematik. Was genau meinst du mit CTL?

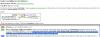
PS: Ich würde ja gerne auf ein Protokoll mit Header-daten umsteigen, leider kann das meine Gegenstelle nicht.
|
|
|
|
|
11.08.2010, 09:57
Beitrag #9
|
GerdW
______________
Beiträge: 17.497
Registriert seit: May 2009
LV2019 (LV2021)
1995
DE_EN
10×××
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
Hallo tanka.
danke für den Hinweis zu den "hierarchischen Clustern"...
Dank der LV-Hilfe bin ich jetzt auch schlauer: Cluster sind ein sogenannter hierarchischer Datentyp.
Du hättest das also nicht extra betonen müssen - es gibt gar keine nicht-hierarchischen Cluster 
CTL: Dateiendung für TypeDefinitions. Du hättest einen Cluster als Typedefinition speichern können, dabei erhälst du ein CTL-File...
|
|
|
|
11.08.2010, 10:05
(Dieser Beitrag wurde zuletzt bearbeitet: 11.08.2010 10:20 von Lucki.)
|

Lucki
Tech.Exp.2.Klasse
Beiträge: 7.699
Registriert seit: Mar 2006
LV 2016-18 prof.
1995
DE
01108
Deutschland
|
Seriellen Datenstrom in hierachischen Cluster parsen
' schrieb:Genau das will tanka nicht haben.
Ich interpretiere tanka aber so, daß er den Inhalt eines komplizierte Cluster mit allem Möglichen drin - drunter auch Arrays und andere Cluster - über eine serielle Schnittstelle möglichst problemlos übertragen haben möchte. Problemlos verstehe ich hier so, daß er nicht Lust hat, auf der Sendenseite einen Header zu programmieren, diesen den Daten voranzuschicken und auf der anderen Seite diesem Haeder dann erst analysieren zu müssen, damit die Daten dann interpretiert werden können.
Ja, richtig, es befinden sich Zusatzinformationen im String, von mir aus nennen wie sie Header. Aber das Entscheidende ist doch, daß niemand (Programmier-) Arbeit damit hat.
Falls Du aber Recht haben solltest, dann kann ich nur sagen: Dann ist das eine willkürliche, schikanöse Vorgabe von tanka, und ich hätte mir nie die Mühe gemacht, auf diesen Beitrag zu antworten..
Edit:
Zitat:An den Variant Datentyp dachte ich auch schon, allerdings ist mir auch bei diesem Datentyp nicht ganz ersichtlich, woher LV weiß, wie der eingehende Datenstrom zu interpretieren ist.
LV weiß das aus der Typbeschreibung. Und da diese immer gleich ist (auch bei variabler Arraylänge im Cluster usw.), muß diese nicht mit übertragen werden, es ist eine Konstante. Und wie man diese erstellt, habe ich ausführlich beschrieben. Aber trotzdem: Wenn Du dazu noch eine Frage hast, gerne..
|
|
|
|
| |

 /
Seriellen Datenstrom in hierachischen Cluster parsen
/
Seriellen Datenstrom in hierachischen Cluster parsen



